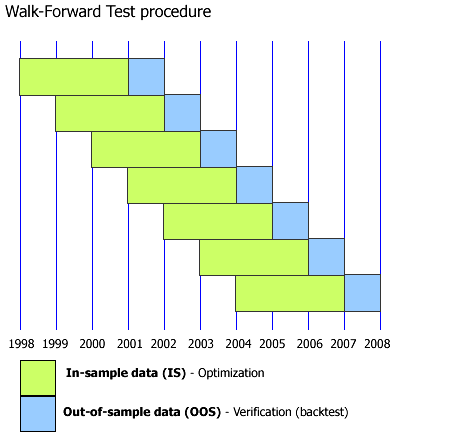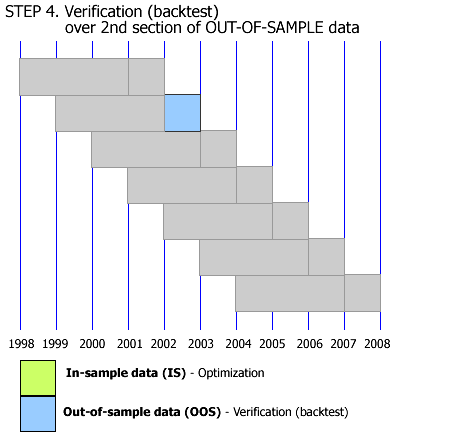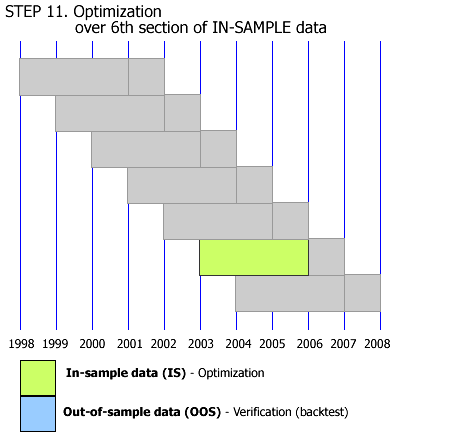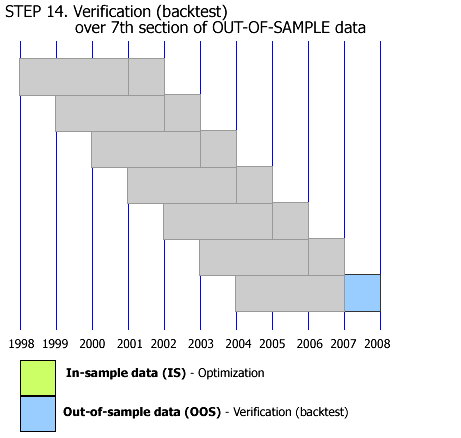
this is potentially one of the worst ways to test a strategy. You are basically overfitting the data not once, not twice, but around 7 times. And you basically completely re-calibrate the strategy from one period to another.
Essentially, this approach grossly disregards market cycles and changes in market dynamics.
Not true. It's certainly far better than fitting insample. As to whether it is overfitted that will depend on how robust the fitting method is, how many years of data are used to fit and so on.
Your reply isn't even consistent. Repeatedly fitting is bad, but you have to account for changes in market dynamics (which one assumes involves repeatedly refitting, unless you fit multiple models to the past and then try and predict which state is coming next using a Markov state machine or similar - an approach with way too many parameters for my likely that will probably end up overfitting).
Take a look how many testing platforms claim to now feature "machine learning" and "genetic algorithms"
lol, yes, so what are you surprised about? Of course this is the case. Let's drop all those fancy words for one second: If you optimize over the same data on which you measure performance then even a middle schooler understands that such results will be better than using unused data for performance evaluation. Has zero and nothing to do with "anchored WFA", robust, non-robust fitting, or whatever other poop you read in some TA books written by authors who must publish books because otherwise they could not make a living.
That is obvious to me as well, but then so what? What we're talking about isn't "poop from TA books" but basic statistics. The guys in the TA books (which I haven't read by the way, despite your inference) might come up with silly names for it but he whole point of this thread is to illustrate that out of sample is better than in sample fitting (which when you strip away the jargon differences is what we're talking about). If that is in a TA book, well it might be a TA book written by an author of dubious motivation, but it's still correct.
It's clear from some replies that not everyone appreciates that, hence me making the point with some actual figures.
I'm also confused by how what I am saying is both 'obvious' and 'factually incorrect'!)
I'm no fan of machine learning eithier, but that isn't what is being discussed here, is it?
I come to this place to learn and to try and pass on something of what I know, and with an open mind to learn from others. Sadly you have zero interest in learning anything, and despite your undoubted claimed expertise you have no desire to pass on your knowledge, only to ridicule and abuse those who disagree with you or know less than you (which is pretty much everybody else as far as I can tell).
Your reasons for doing this I can only imagine, but Freud would have a field day. Perhaps you are trying to reproduce the macho camaraderie you once had on a trading floor. I pity you. For someone who claims to spend 12 hours a day working still to have time to come on here is very strange. I suggest you try and spend more time doing other things. It might make you a better person.
I've seen this kind of behaviour from you on too many threads now. You are rude, and you are a bully. Worst still you are boring. You sir, are ignored.