You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Is backtesting necessary before Walk Forward Analysis?
- Thread starter kojinakata
- Start date
Suppose you backtest and don't like what you see. You're probably going to drop the rule, or modify it
You shouldn't really take any action at all, since you have forward information at this point.
But if you're going to backtest and ignore the results, then what's the point of doing it?
To be honest I find the dichotomy artificial, and it's not a distinction I'd seen before, so some of the argument might be that I am not understanding the nomenclature. I don't really understand what you mean by 'forwardtesting'....?
To me WFA is a form of backtesting*, and in my opinion the only valid one.
* other time domains are fully in sample, half out of sample (fit on first period A, test on second period B), half and half (fit on A test on B, fit on B test on A), knock one out (fit on all years except 2002, test on 2002; fit on all years except 2003, test on 2003...)
It's easier and quicker to refer to this: Developing A Plan. Observation, backtesting, forwardtesting, simtrading, real trading.
WFA and forward testing results are conditioned on the data sample(s). Example: you apply WFA to a trend-following system. The first optimization sample involves a nice trend but the walk forward sample is a sideways market. The system then fails in the forward sample. There are problems here that some do not realize as signals may overlap. Do you consider any open signals when you transition to the forward sample or wait for a fresh signal? These can produce wide variations in results. I find WFA useless waste of time. Forward testing can be useful. One should rely on statistical analysis. How was your system developed? Did you conceive it or you read about it in some book or article? Was the system data-mined? In those cases nothing will save you. The only way to decrease the chances that after a year you will hear the word "trading" and run like 90% of others before you is to make sure your system works in as many markets as possible. This means that your system has a sound basis compatible with market structure. Then you should limit risk per position to less than 1%. Those are the first step to survival. Making profits comes next. I highly recommend PART I of this article. I find the author's points useful.
What? Have you studied the basics of time series analysis? Pretty much everything you said in this post is factually incorrect.
Yes I have. And the advanced stuff as well.
And I politely disagree that everything I said is incorrect, since it's clear that we're talking about different definitions of the terms 'WFA' and 'backtesting'.
Are you always this rude?
Anyway here is what I personally do, which will hopefully sidestep any arguments that are mainly about definitional disagreements.This works for me, because I trade fully systematically with a relatively large number of fairly simple trading rules, and then use the combination of their forecasts.
* select / define some rules
Ideally you wouldn't look at any real performance data at all when doing this (what I would define as 'in sample' backtesting). Otherwise you would be at risk of pre-selecting only rules that were good, which will inflate any performance numbers you look at subsequently (the original post I made).
Rules ideally should have a minimum of parameters, and ideally it should be possible to define sensible 'default' values for these parameters.
So we aren't selecting rules on the basis of performance, but on behaviour. So for example does it capture the kind of behaviour I expect, i.e. buy into uptrends, cut in reversals? Is the holding period appropriate, given the length of forecast we're trying to make? Does the rule add some diversification or is it 99% correlated to another rule? Does the algorithim have corner cases, how does it handle missing values, that kind of thing.
You can use artifical data to make these kinds of decisions. You can also use 'scenarios' i.e. snapshots of historical events which you run the rule over and check the behaviour makes sense. If you don't have any choice, and you're disciplined, you can use real data; again though you must avoid the temptation to look at p&l.
Note this doesn't mean you will definitely get realistic achievable historical performance. You're probably still only testing stuff you know sort of works (there was another thread about this here) from your own experience or reading literature or reading about someone elses backtest. Eg we know momentum generally works, we know carry works, we know certain kinds of groups of assets display mean reverting behaviour? This is an implicit overfitting, which we can't get away from unless we use relatively general rules with larger numbers of parameters fitted entirely from the data (a method which has its own pitfalls).
Other more subtle reasons are that long, unrepeatable, secular trends in the past inflate backtested performance.
* decide what weights to choose when combining rules
This is a portfolio allocation problem. We want to upweight good rules, although not by too much unless there is a clear statistical difference in performance. So we use real performance data, but only from the past at each point of the simulation.
I do this on an 'expanding window out of sample' basis (which is what I mean when I say WFA) using non parametric bootstrapping. Any technique that doesn't 'over extrapolate' insignificant differences in performance into radically different allocations is fine. The important thing is we're only using past data to fit with.
* backtest or simulate
With the rules, and the dynamically changing allocations, look at the performance. This is purely to get an idea of the likely behaviour of the system to calibrate our expectations about things like drawdown levels and sharpe ratio, and hence make sure our risk target isn't to aggressive.
We shouldn't make any changes to rules or parameters at this stage or they will be entirely in sample.
* select / define some rules
Ideally you wouldn't look at any real performance data at all when doing this (what I would define as 'in sample' backtesting). Otherwise you would be at risk of pre-selecting only rules that were good, which will inflate any performance numbers you look at subsequently (the original post I made).
Rules ideally should have a minimum of parameters, and ideally it should be possible to define sensible 'default' values for these parameters.
So we aren't selecting rules on the basis of performance, but on behaviour. So for example does it capture the kind of behaviour I expect, i.e. buy into uptrends, cut in reversals? Is the holding period appropriate, given the length of forecast we're trying to make? Does the rule add some diversification or is it 99% correlated to another rule? Does the algorithim have corner cases, how does it handle missing values, that kind of thing.
You can use artifical data to make these kinds of decisions. You can also use 'scenarios' i.e. snapshots of historical events which you run the rule over and check the behaviour makes sense. If you don't have any choice, and you're disciplined, you can use real data; again though you must avoid the temptation to look at p&l.
Note this doesn't mean you will definitely get realistic achievable historical performance. You're probably still only testing stuff you know sort of works (there was another thread about this here) from your own experience or reading literature or reading about someone elses backtest. Eg we know momentum generally works, we know carry works, we know certain kinds of groups of assets display mean reverting behaviour? This is an implicit overfitting, which we can't get away from unless we use relatively general rules with larger numbers of parameters fitted entirely from the data (a method which has its own pitfalls).
Other more subtle reasons are that long, unrepeatable, secular trends in the past inflate backtested performance.
* decide what weights to choose when combining rules
This is a portfolio allocation problem. We want to upweight good rules, although not by too much unless there is a clear statistical difference in performance. So we use real performance data, but only from the past at each point of the simulation.
I do this on an 'expanding window out of sample' basis (which is what I mean when I say WFA) using non parametric bootstrapping. Any technique that doesn't 'over extrapolate' insignificant differences in performance into radically different allocations is fine. The important thing is we're only using past data to fit with.
* backtest or simulate
With the rules, and the dynamically changing allocations, look at the performance. This is purely to get an idea of the likely behaviour of the system to calibrate our expectations about things like drawdown levels and sharpe ratio, and hence make sure our risk target isn't to aggressive.
We shouldn't make any changes to rules or parameters at this stage or they will be entirely in sample.
It's easier and quicker to refer to this: Developing A Plan. Observation, backtesting, forwardtesting, simtrading, real trading.
Thanks. Good to have some helpful people. As I said on my other post, for me it would be using my terminology:
Observation & rule design,
backtesting (or simulation) done using rolling out of sample data,
paper trading,
real trading.
I hadn't heard the term 'walk forward testing' till about 6 months ago, and 'forward testing' not until yesterday; despite about a decade in the industry. Which goes to show there isn't a common dictionary on this stuff.
Please properly define what you understand under Walk Forward Analysis because either you or a lot of other users here seem to base their understanding on a divergent definition. Are you talking about using historical data to test a strategy that has been parameterized with previous data or are you talking about a strategy that has been parameterized today and you now want to wait a year to run the strategy over live incoming data before you deploy? Both apply new time series data after the parameterization process.
I am talking about this:
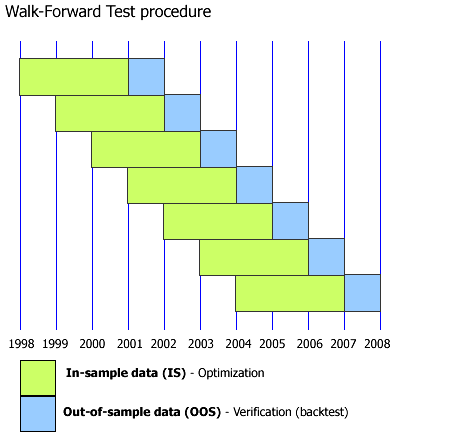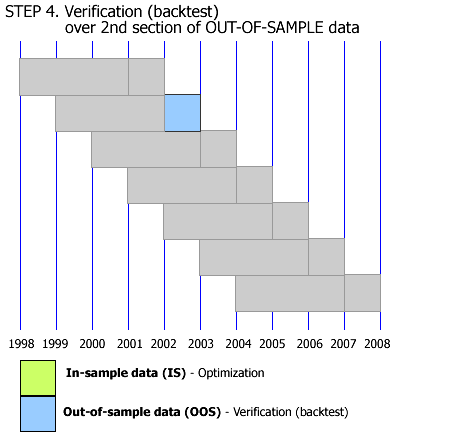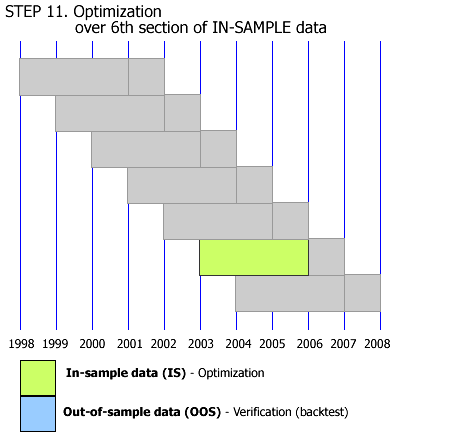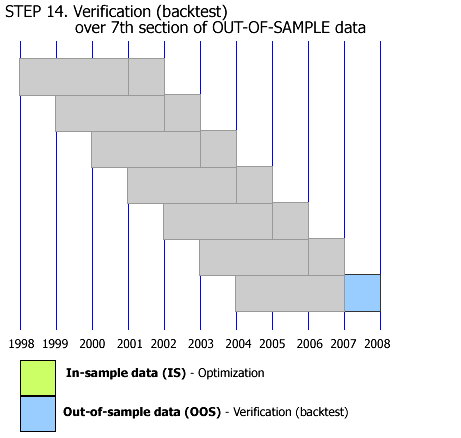
This is what I mean by Walk Forward Analysis, assuming the current date is the start of the year 2008. So all analysis&tests are done with historical data. From what I've read in several Wiley Trading series books, this is the only WFA definition there is. Optimizing the strategy from 2005 till 2008, and "paper trading" it in 2009, is called Forward Testing as far as I know. I am only talking about the process in the gif animation done with historical data. Is it clear now?
I have a staff of 8 that works 2.5 shifts a day, they day trade and there is one and they alternate full time coding, I lease seats so I can save money from fees, I just added another member to make it three for my long term positions as I am adding options to instruments I seek profits from it. I use to be like you and work 100 hours a week but bad health finally caught up to me these past seven years. I have done everything I wanted to do in day trading, and my time for new projects lay in long term cause except for one year, long term has always did better than short term. I been trading 37 years, I have owned a brokerage back in the 90s, managed money, consultant for energy and wheat grower companies, so my future I have no more to prove. If you think I am part time, so be it, but I have come to where I am just tired. I retired from government job I had 1999 when I was 42yo, all these years of trading was never work, when you do what you love.I still do not really understand what you are trying to say.
From your last sentence I get you spend 1 hour per day now on this endeavor? Well, I spend about 12 hours every single day and still outsource tons of projects and work to programmers and quants because I cannot get all the work done myself. 1 hour sounds more like you take this as a hobby rather than a serious and competitive career.