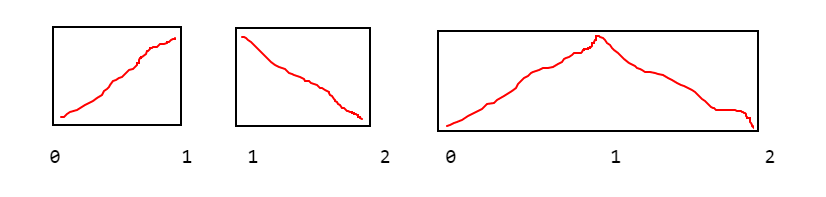
Suppose there are three periods A,B,C
SegA runs 1.0→2.0
SegB runs 2.0→1.0, and
SegC runs 1.0→1.0
Models performing best in
SegA would show positive (Cartesian) linear behavior,
SegB would show negative linear behavior, while
SegC would exhibit a graceful curvelinear arc and do best with a second-order parameter of negative sign, to degrade (and eventually overwhelm) a positive first-order parameter.
So....
1) The border matters.
2) W.R.T. subset performance, SegA+SegB =/= SegC.
SegA runs 1.0→2.0
SegB runs 2.0→1.0, and
SegC runs 1.0→1.0
Models performing best in
SegA would show positive (Cartesian) linear behavior,
SegB would show negative linear behavior, while
SegC would exhibit a graceful curvelinear arc and do best with a second-order parameter of negative sign, to degrade (and eventually overwhelm) a positive first-order parameter.
So....
1) The border matters.
2) W.R.T. subset performance, SegA+SegB =/= SegC.
")
")