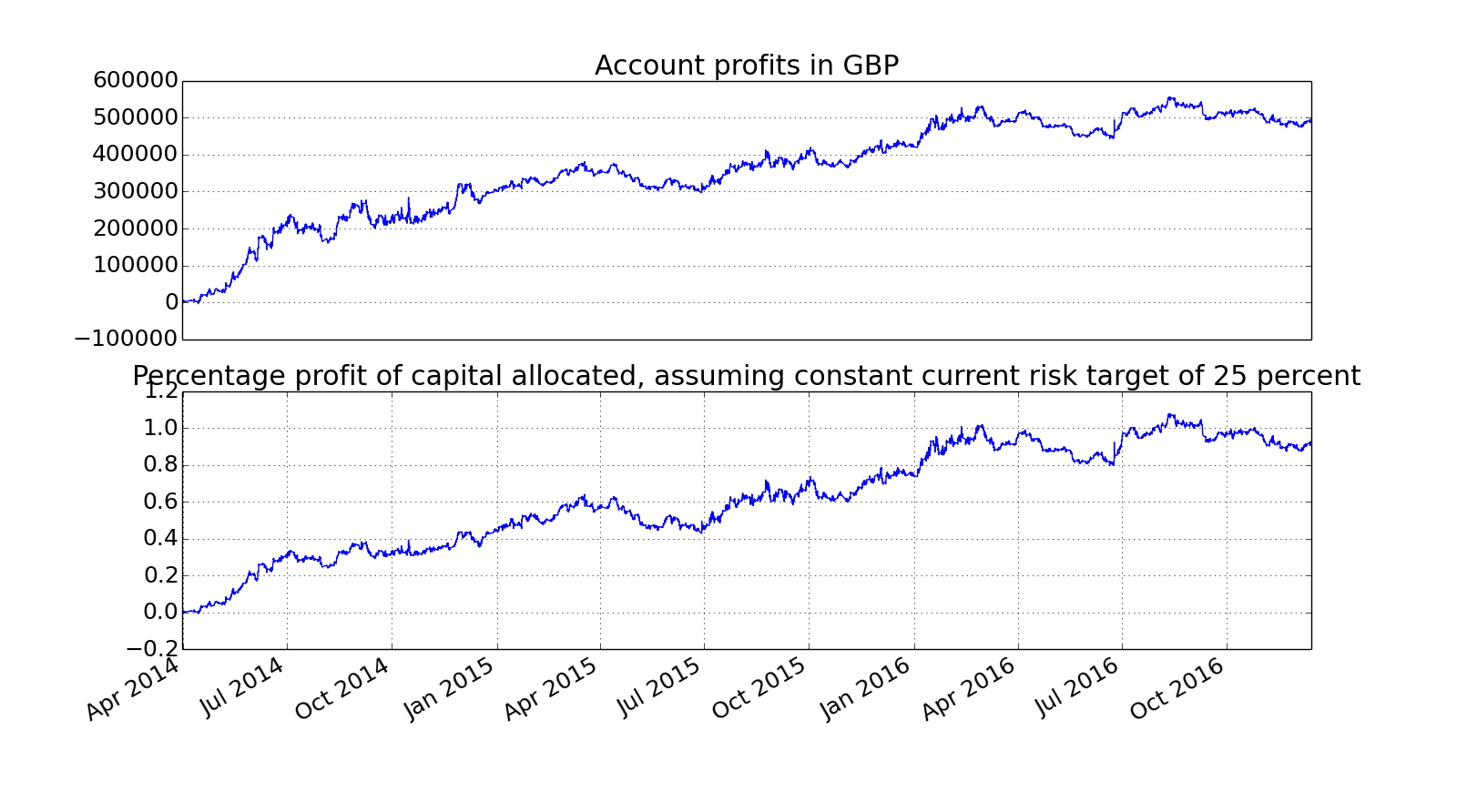
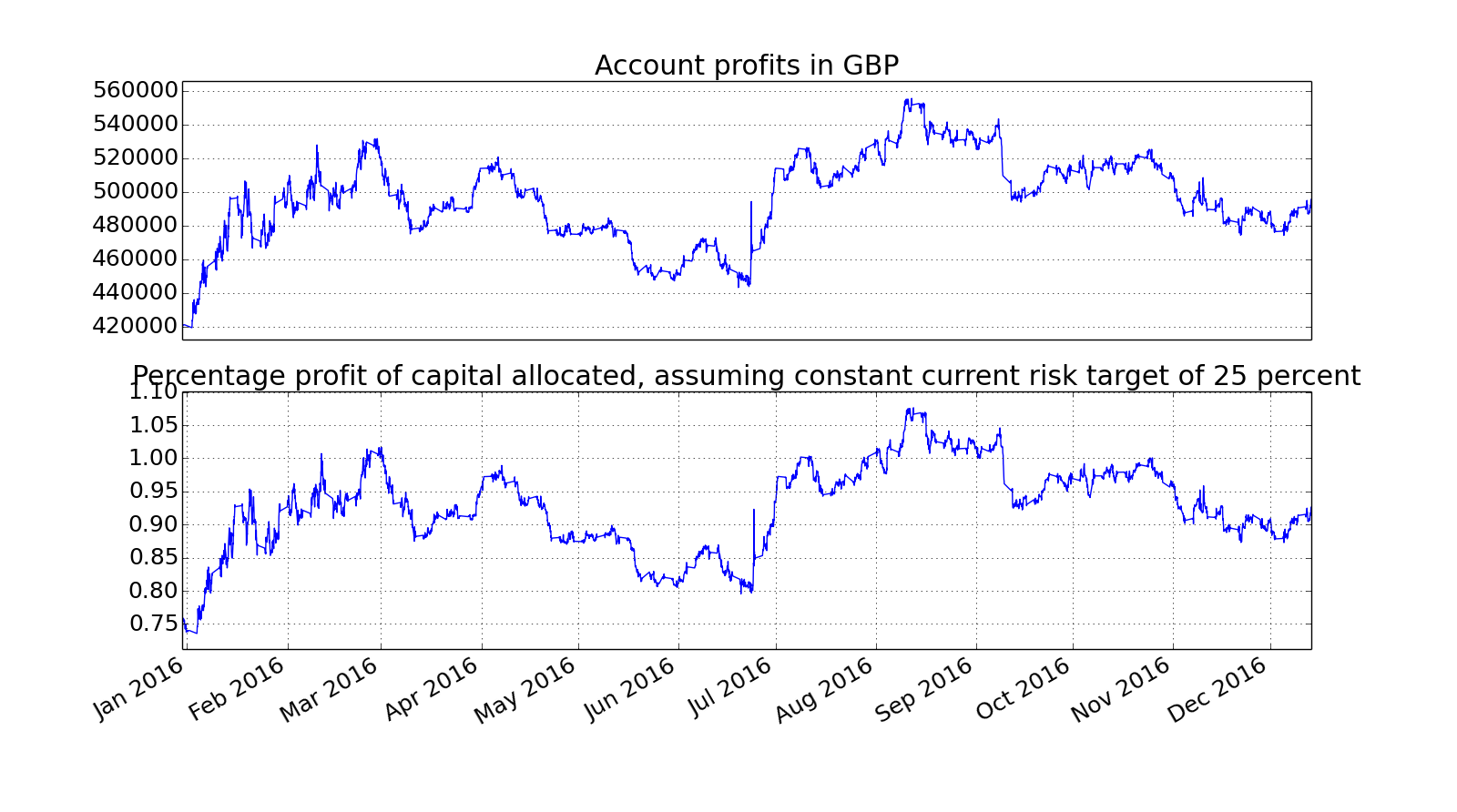
Hi GAT, a discussion on
nuclearphynance about data snooping bias mitigation using Cross-Validation vs block bootstrapping caught my attention...wondered if you'd comment on the comparison of them, since you discuss non-parametric bootstrapping on your blog. Bolded text below is my mod, to indicate particular items of interest.
"Both approaches are estimating the magnitude of generalization error from test-set variance.
Cross-validation is doing it by training with real data, then comparing that to error round in real, but unfitted data. The random-bootstrap approach is doing it by training with real data than comparing to training with random data.
The former approach is superior for a number of reasons:
1) You need a way to reliably produce random data that's sufficiently similar to real data. The source blog suggests bootstrap, but that's not robust. There may be inter-temporal structure to the data that isn't due to training set variance, yet still causes overfitting. E.g. imagine at short time horizons returns tend to mean-revert in real data. You could overfit on this data by finding a signal that buys securities with consistently >X% mean-reversion. This could purely be noise in the training data, producing positive returns in sample. Yet the random bootstrapping could still show much lower performance because at any given time there'd be much different distribution for recent mean-reversion in randomly shuffled data.
2) Comparing real to random only tells you if your system did better than one based on totally pure randomness. That's all well and good, but there's a world of difference from knowing that your system isn't 100% data-mining bias, and knowing how much of your backtested performance is attributable to it. That's important not only for setting risk-tolerances and transaction cost thresholds, but also for comparing different parameterizations of a strategy. If Strategy A uses fewer free-parameters than Strategy B, but has lower performance, knowing that they both out-performed random doesn't help you pick. With cross-validation you can directly compare in out-sample space.
3)
If you're dealing with any-sort of non-convexity in training, then the random-real comparison is vulnerable to multiple equilibrium. Say it's completely data-mining, how do you know the real-parameterization didn't just stumble into a better than average optimization basin? In that case it will look a lot better than most of the random comparisons. Yet the system is still junk. For K>=10, CV, all the in-sample parameterizations are highly likely to be very similar. That makes it easy to reason about their out-sample performance. Moreover, even if they're not, cross-validation will still reveal data-mining bias even if there are highly-biased but infrequent basins.
4) NFL theorem tells us that we have to be giving up something for cross-validation over real-random comparison. It's true that CV requires us to "sacrifice" 1/K of the training data. In this case CV overestimates generalization error because it trains on less data than we would when training on the entire set. But if you're using K>=10, its most likely that your learning curve if basically flat at 0.9N samples for any sensible system.